-
- Downloads
init
parents
No related branches found
No related tags found
Showing
- JP pres/Uni_Logo_blau.jpg 0 additions, 0 deletionsJP pres/Uni_Logo_blau.jpg
- JP pres/aug1.png 0 additions, 0 deletionsJP pres/aug1.png
- JP pres/aug2.png 0 additions, 0 deletionsJP pres/aug2.png
- JP pres/aug3.png 0 additions, 0 deletionsJP pres/aug3.png
- JP pres/calnov2024.jpg 0 additions, 0 deletionsJP pres/calnov2024.jpg
- JP pres/cg.png 0 additions, 0 deletionsJP pres/cg.png
- JP pres/cg1.png 0 additions, 0 deletionsJP pres/cg1.png
- JP pres/cg2.png 0 additions, 0 deletionsJP pres/cg2.png
- JP pres/corner2.png 0 additions, 0 deletionsJP pres/corner2.png
- JP pres/cornerroute.png 0 additions, 0 deletionsJP pres/cornerroute.png
- JP pres/feb_presentation.tex 662 additions, 0 deletionsJP pres/feb_presentation.tex
- JP pres/m1.png 0 additions, 0 deletionsJP pres/m1.png
- JP pres/m2.png 0 additions, 0 deletionsJP pres/m2.png
- JP pres/m3.png 0 additions, 0 deletionsJP pres/m3.png
- JP pres/memoryless.png 0 additions, 0 deletionsJP pres/memoryless.png
- JP pres/newplot.png 0 additions, 0 deletionsJP pres/newplot.png
- JP pres/newplot2.png 0 additions, 0 deletionsJP pres/newplot2.png
- JP pres/newplot3.png 0 additions, 0 deletionsJP pres/newplot3.png
- JP pres/rf_clf1_roc.png 0 additions, 0 deletionsJP pres/rf_clf1_roc.png
- JP pres/rf_clf2_roc.png 0 additions, 0 deletionsJP pres/rf_clf2_roc.png
JP pres/Uni_Logo_blau.jpg
0 → 100644
{kind=link}
151 KiB
JP pres/aug1.png
0 → 100644
{kind=link}
67.7 KiB
JP pres/aug2.png
0 → 100644
{kind=link}
67.9 KiB
JP pres/aug3.png
0 → 100644
{kind=link}
73 KiB
JP pres/calnov2024.jpg
0 → 100644
{kind=link}
245 KiB
JP pres/cg.png
0 → 100644
{kind=link}
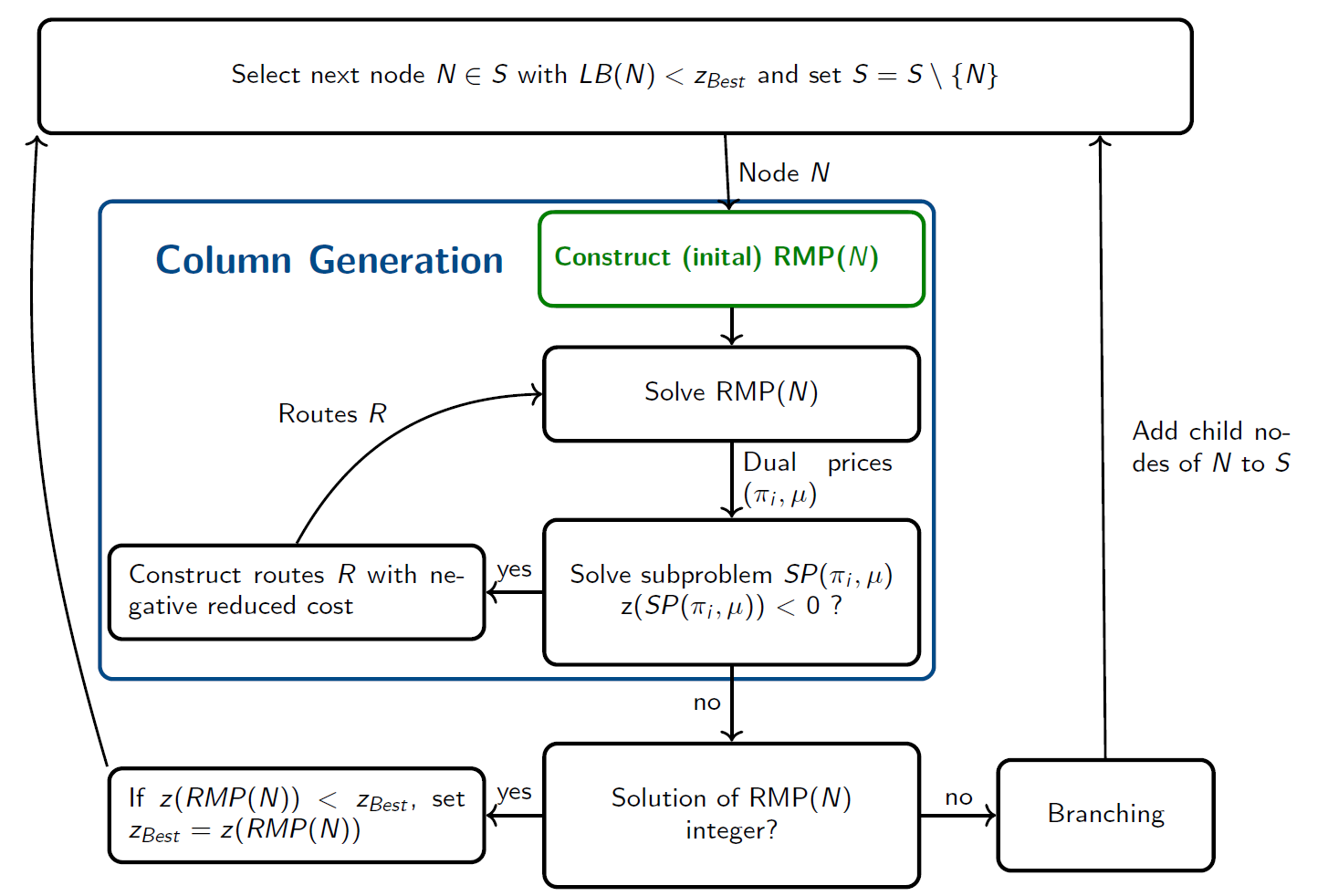
133 KiB
JP pres/cg1.png
0 → 100644
{kind=link}
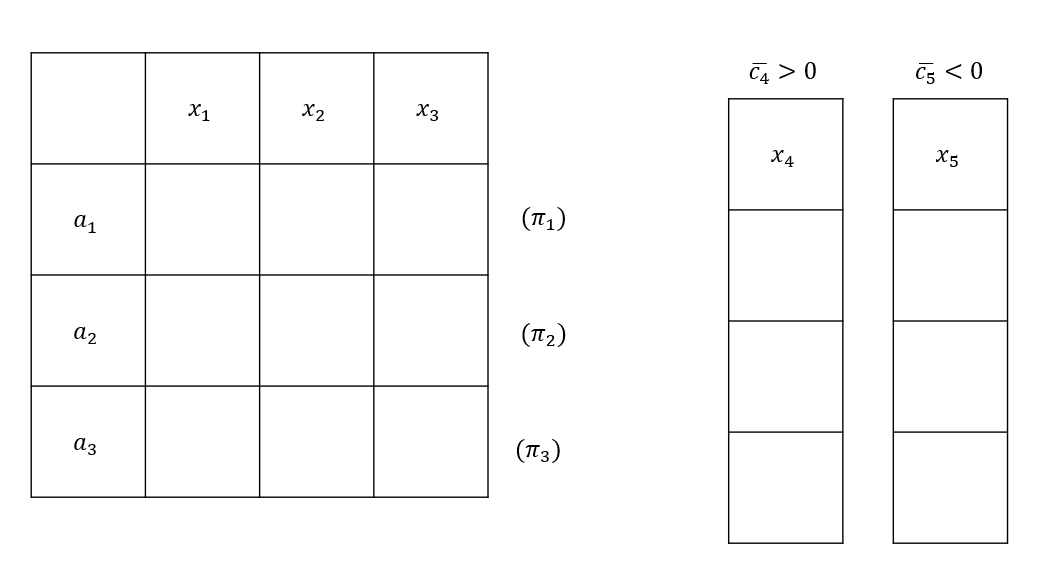
16.1 KiB
JP pres/cg2.png
0 → 100644
{kind=link}
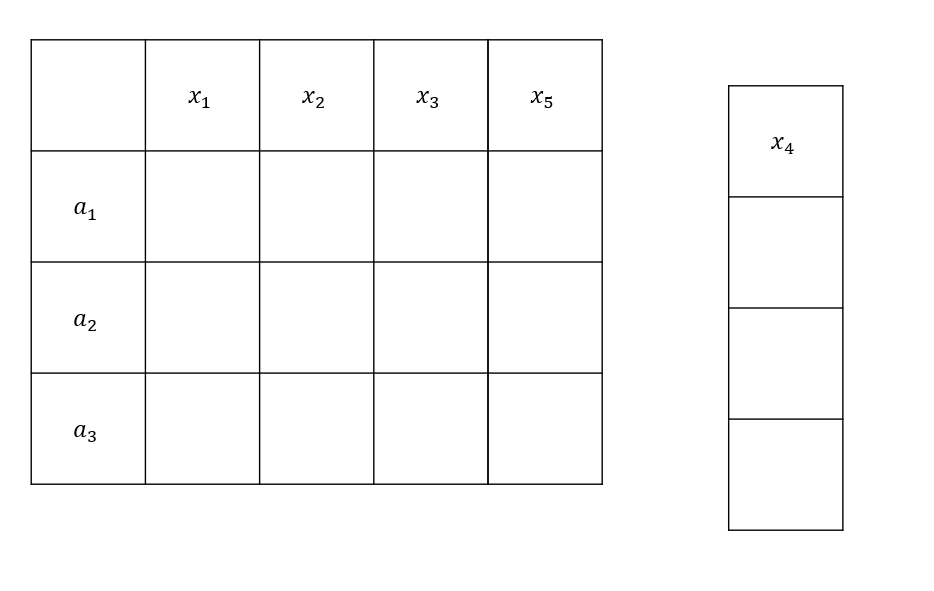
10.1 KiB
JP pres/corner2.png
0 → 100644
{kind=link}
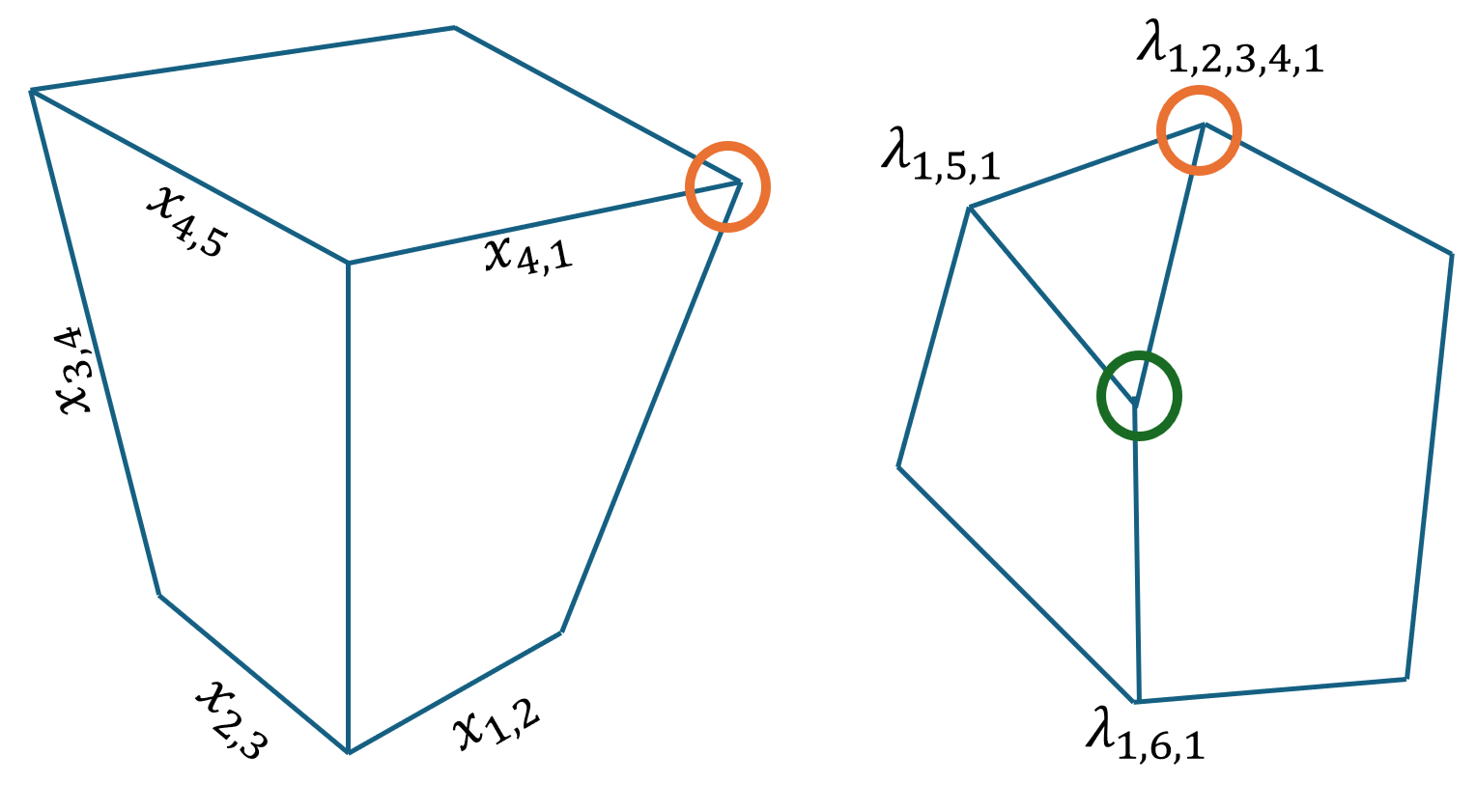
88.8 KiB
JP pres/cornerroute.png
0 → 100644
{kind=link}
50.9 KiB
JP pres/feb_presentation.tex
0 → 100644
JP pres/m1.png
0 → 100644
{kind=link}
38.7 KiB
JP pres/m2.png
0 → 100644
{kind=link}
39.4 KiB
JP pres/m3.png
0 → 100644
{kind=link}
40.2 KiB
JP pres/memoryless.png
0 → 100644
{kind=link}
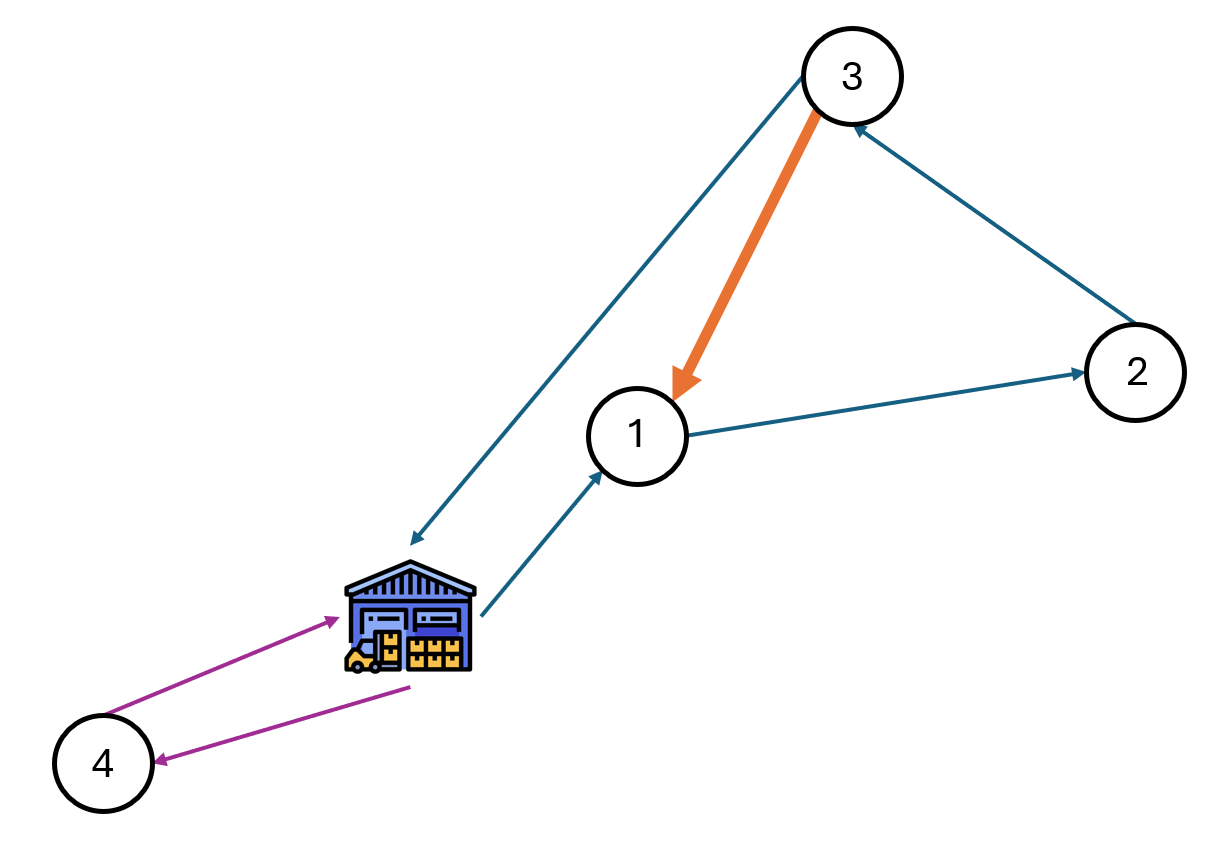
53.5 KiB
JP pres/newplot.png
0 → 100644
{kind=link}

125 KiB
JP pres/newplot2.png
0 → 100644
{kind=link}
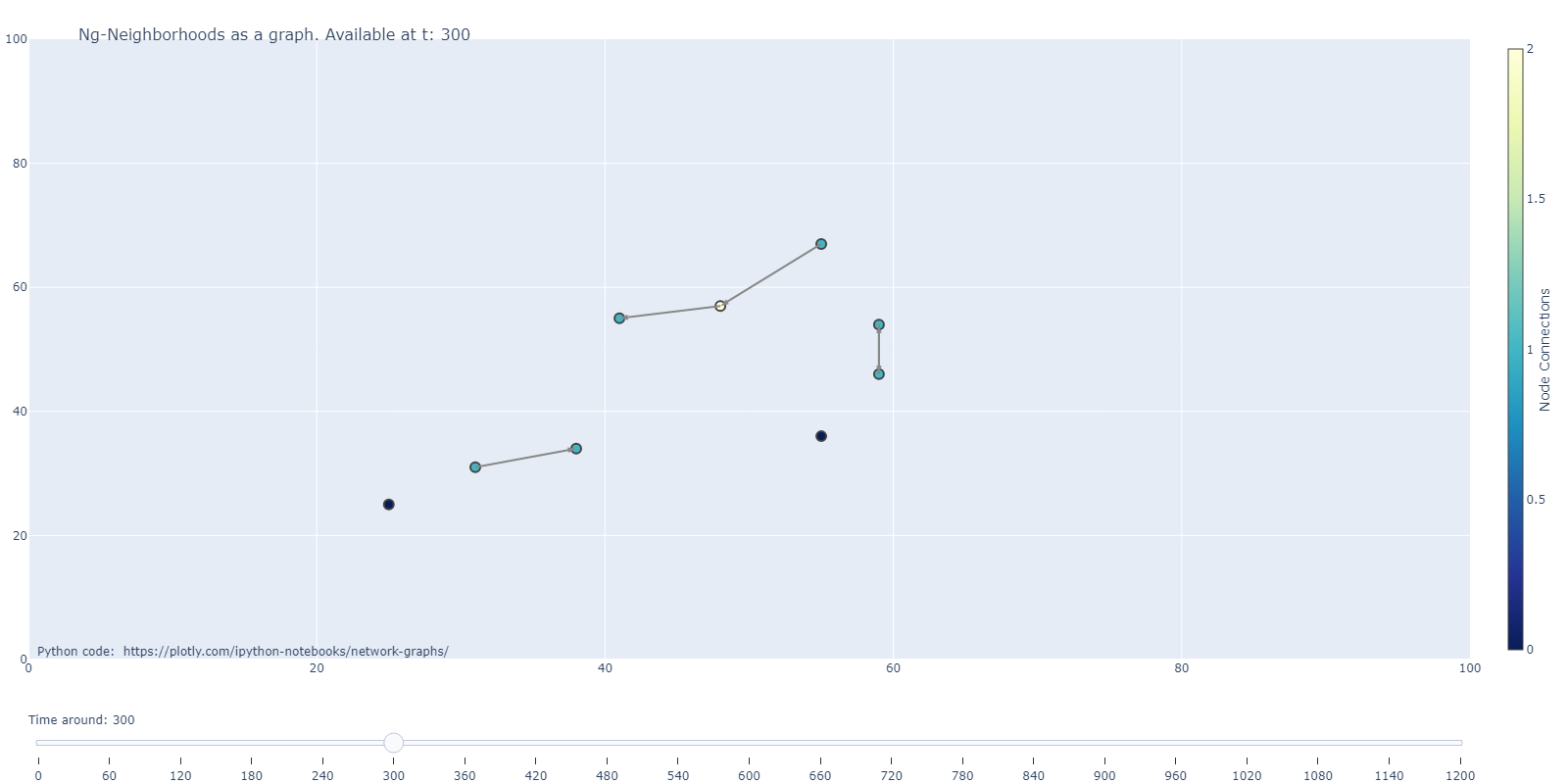
76.2 KiB
JP pres/newplot3.png
0 → 100644
{kind=link}
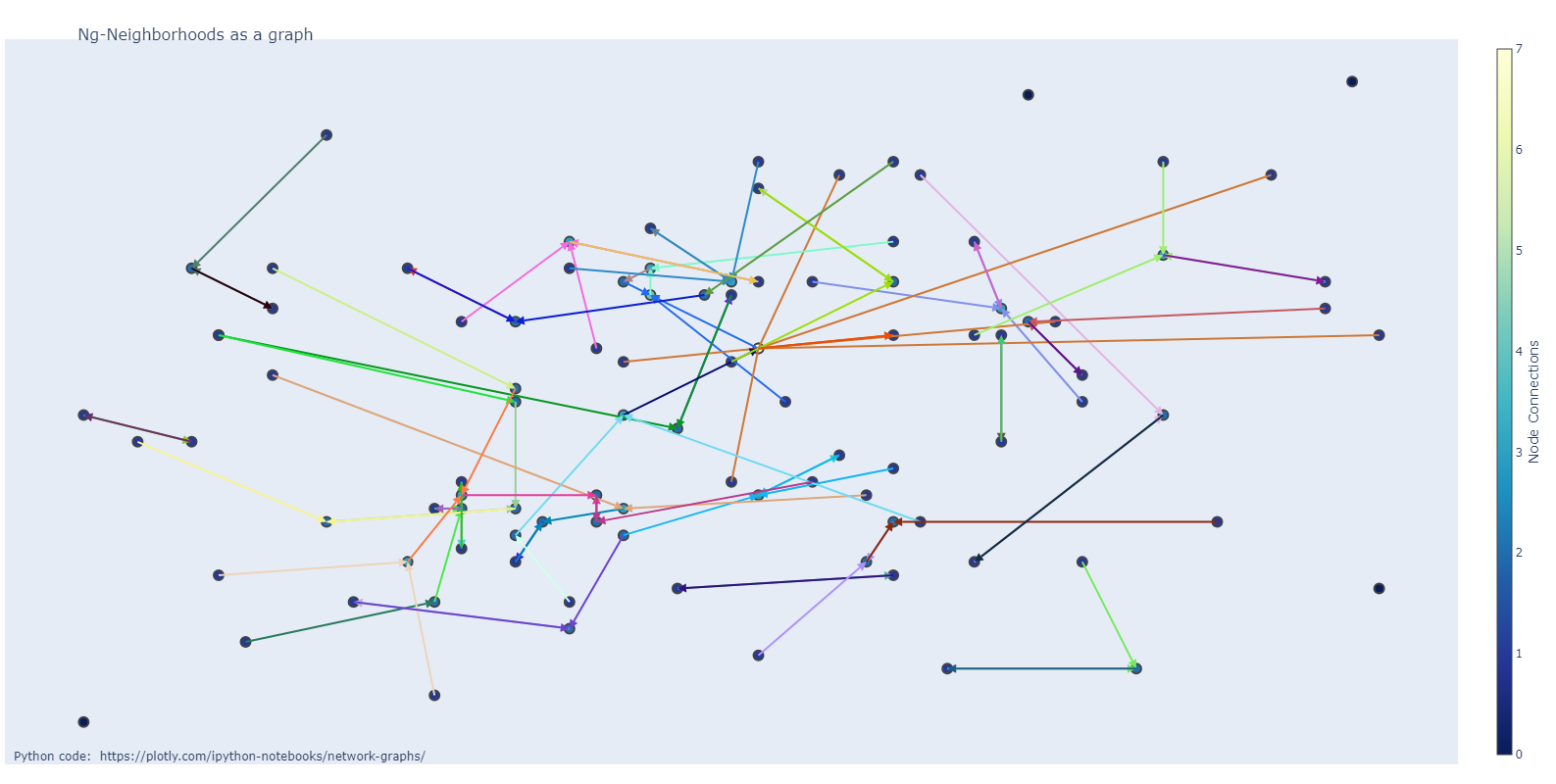
191 KiB
JP pres/rf_clf1_roc.png
0 → 100644
{kind=link}
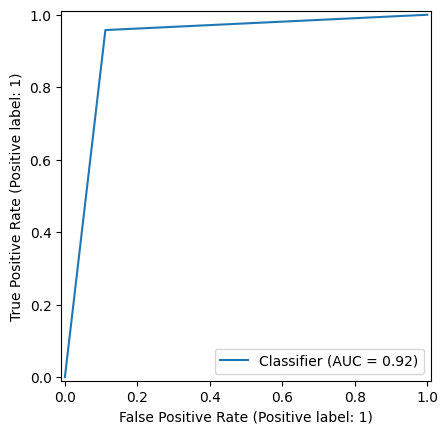
22.3 KiB
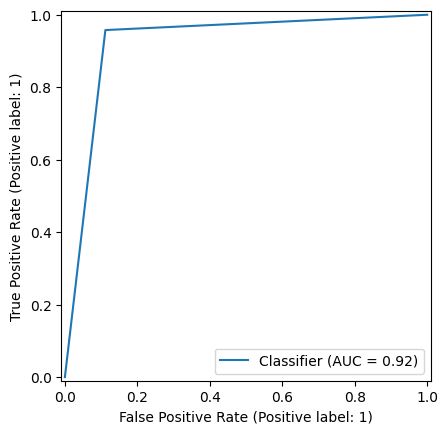
JP pres/rf_clf2_roc.png
0 → 100644
{kind=link}
22.3 KiB